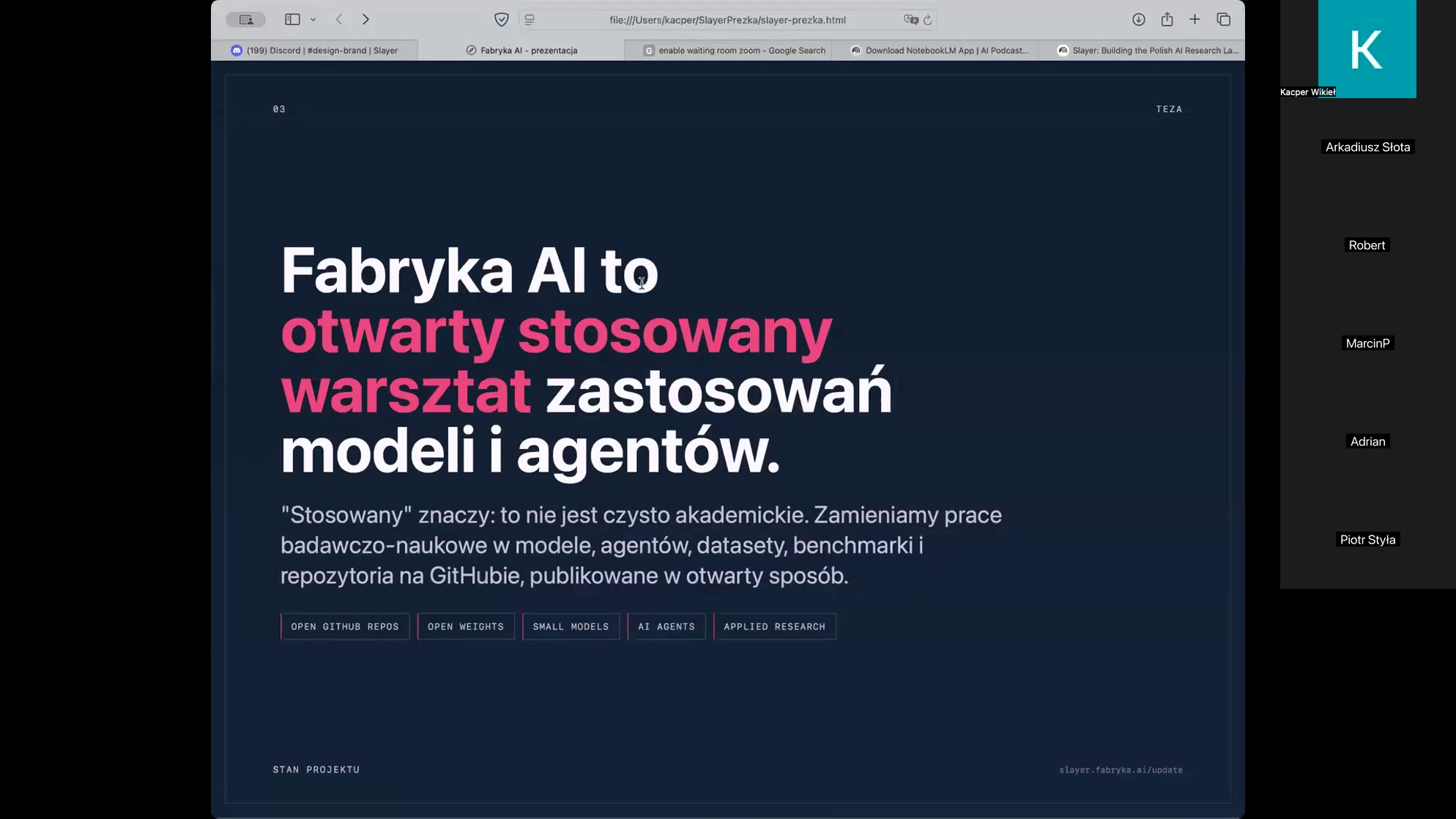
Slajd 49 · 51:14–1:18:19
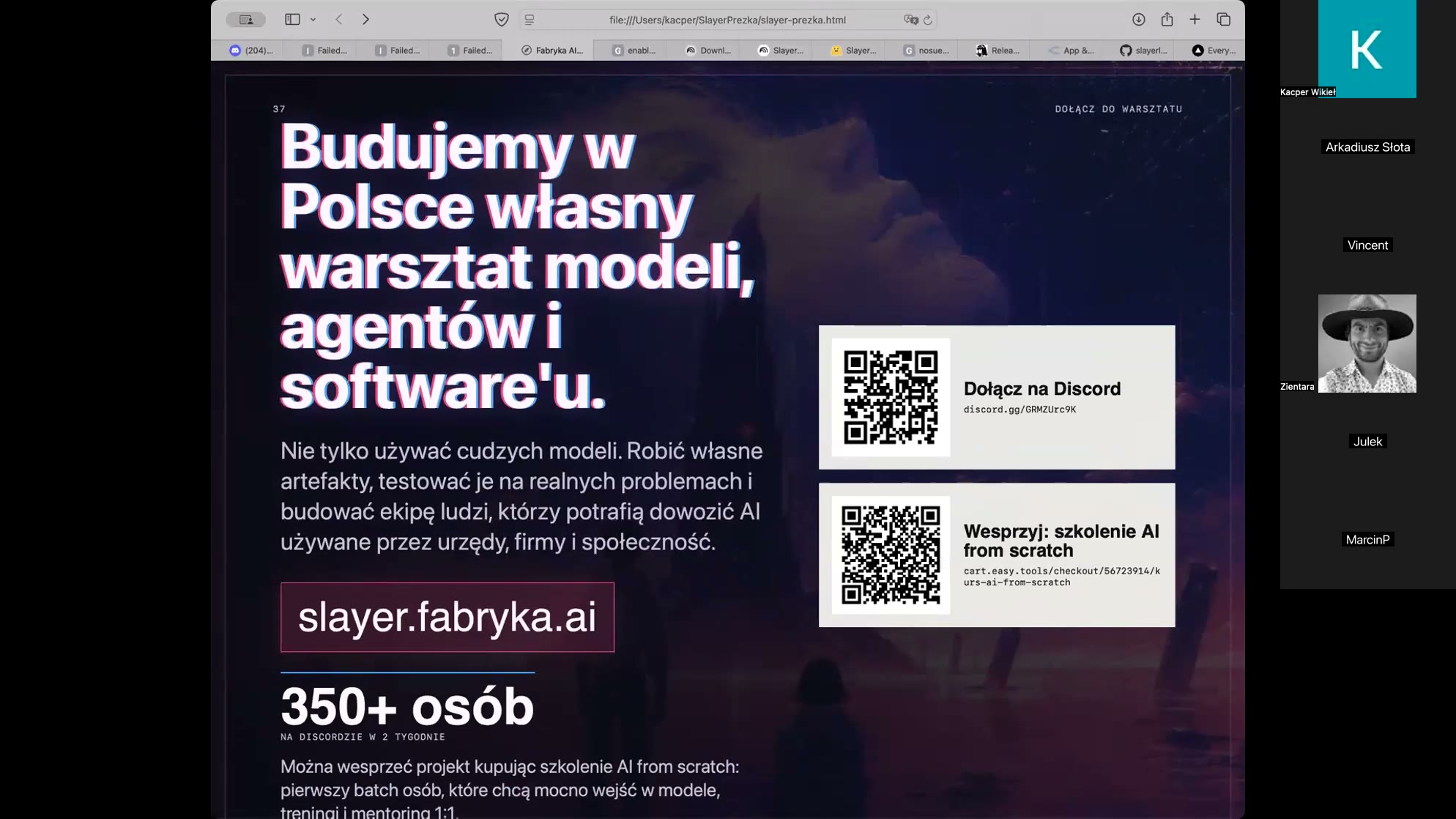
CTA: zeskanuj kod QR i dołącz do Discorda. Kto chce finansowo wesprzeć rozwój projektu, może kupić szkolenie (700 zł) — to forma komercjalizacji dająca od razu wartość: godziny materiałów plus mentoring 1:1 z prowadzącym lub zespołem. Kolejne kroki: kontakt indywidualny dziś i jutro, w środę mailing z rozpiską i szczegółami; szkolenie startuje w środę. Uczestnictwo w laboratorium nie wymaga żadnych pieniędzy — działa też odwrotnie: kto przyjdzie na Discorda z ciekawym pomysłem, dostaje od Slayera wsparcie merytoryczne oraz zasoby (godziny na kartach graficznych, API, know-how).
Gość: Igor (NVIDIA) — wspiera lokalne inicjatywy AI w Europie Środkowo-Wschodniej i adopcję oprogramowania NVIDIA. NVIDIA poza kartami graficznymi tworzy dużo oprogramowania, o którym mało kto wie. Sposób, w jaki wielkie korporacje układają dziś stos AI, to "five-layer cake": energia, chipy, infrastruktura (hyperscalerzy), modele i aplikacje. Problem modeli w językach innych niż angielski: dużych labów (OpenAI, Anthropic) skupiają się na angielskim i mają wielokrotnie więcej GPU; danych w innych językach jest znacznie mniej, są nieprzefiltrowane i pełne niuansów. Żeby zrobić dobry polski model (jak Bielik) potrzeba kart, ludzi i dużej ilości wyczyszczonych, wykurowanych danych.
NVIDIA pokazuje, jak budować takie modele — od udostępniania datasetów po modele konkurencyjne (nie z najnowszymi Opusami czy GPT, ale z Qwenami i DeepSeekami). Modele Nemotron są open source, a razem z nimi udostępniane są zbiory treningowe oraz recipes i cookbooki. Cel: builderzy i większe laby nie mają już argumentu, by ich model był gorszy. Luka między modelami zamkniętymi a open source coraz bardziej się zamyka — otwarte modele bywają równie dobre za ułamek wielkości, co napędza popyt na rozwiązania on-prem.
Historia inicjatywy: Nemotrony trenowane od 2024 r.; zaczęło się od dodania reasoningu (chain of thought) do Llamy. Przy Nemotron 2 zmieniono architekturę na Mamba MoE — w odróżnieniu od transformerów Mamba skaluje compute liniowo przy długim kontekście (transformer kwadratowo), co umożliwia np. 1 mln kontekstu. Większość builderów (Qwen, DeepSeek, Nemotron, GLM) przechodzi na Mamba MoE. Nowe Nemotrony to jedne z pierwszych otwartych modeli rywalizujących z największymi, z pełnym wglądem w to, jak były trenowane.
Narzędzie Personas: generuje syntetyczne datasety odwzorowujące populacje (USA, Japonia, Indie, Korea, Singapur). NVIDIA rozważa stworzenie takiego zbioru z zespołem Bielika, który ma dużo danych i doświadczenia. NVIDIA współpracuje z kilkoma europejskimi labami budującymi LLM-y w lokalnych językach (m.in. Bielik). Trudność: wartość lokalnego LLM jest nieoczywista dla przeciętnego użytkownika, bo może za 20 dolarów użyć OpenAI, który mówi po polsku koślawo, ale taniej i użytecznie. Uwaga: lokalne modele są mniejsze i często trenowane "żeby zostały wytrenowane", a nie pod konkretny use case — w Slayerze jest szansa eksperymentować i drastycznie optymalizować modele (80 tys. w kredytach to sporo).
Kacper dodaje: nie chodzi o robienie modelu dla samego modelu, tylko o zbudowanie ekipy ludzi pracujących w otwarty sposób — otwartej jednostki badawczej generującej artefakty i publikacje. To trochę "hello world": zaczynamy od rzeczy edukacyjnych, potem płynnie przechodzimy do finetuningu na trace'ach agentowych pod agentowe use case'y. Firmy zgłaszają zainteresowanie dedykowanymi finetuningami pod enterprise, a w Polsce jest dużo seniorów i programistów chcących się uczyć — łączymy jedno z drugim.
Gość: Julek (Juliusz) — trenuje duże transformery w RTB House (adtech); wcześniej Huawei (LLM-y, voice assistant), Google (Gemini Code Assist), wykłada NLP na UW. W RTB House trenują na TPU (Google), które są ok. 3x tańsze per compute niż GPU; dzięki dobrym modelom do vibe-codingu przeniesienie kodu na Jax nie jest trudne. TPU łączą się w topologię typu torus (kostka), więc komunikacja między nimi jest tańsza sprzętowo niż w GPU (które potrzebują drogich NVSwitchy); są dobrze dostępne, zwłaszcza w USA — warto rozważyć dla maksimum compute'u za dolara.
Dwa źródła nauki polecane przez Julka: (1) Discord — sam uczył się NLP ~8-10 lat temu na Discordzie LAION (non-profit lab researcherów, głównie z USA), czytając dyskusje o retrievalu, Mambie itd. (uwaga: Mamba to architektura sprzed ok. 4 lat i długo była raczej zabawką — dlatego warto konsultować z innymi, czy coś ma sens). (2) Kaggle — hostuje zawody AI (np. AI Mathematical Olympiad); topowe zespoły piszą write-upy z opisem rozwiązania, z których można się uczyć. Żeby być najlepszym, trzeba wzorować się na najlepszych. Wiele jest do zrobienia w datasetach i scaffoldingu — zwycięzcy AI Math Olympiad zebrali zadania matematyczne z forów, czego nikt wcześniej nie zrobił. Można wybrać problem, spróbować być najlepszym i zdobyć rozpoznawalność. Julek chce wspierać projekt, m.in. jako alternatywę, gdyby zamknięte modele (Claude, ChatGPT) kiedyś odcięły dostęp.